Chrome で ctrl2cap が動作しない不具合の解決
普段、ctrl2cap というソフトウェアを使用して、Caps Lock を Ctrl として動作させています。
いつからだったか、これが Chrome でうまく動作しなくなりました。
Ctrl キーはそのまま動作するのに、Caps Lock だとおかしな挙動になるのです。
通常のブラウジングだけならまだしも、Jupyter でも同じようになるので、だいぶ困っていました。
いろいろ調べてみたところ、ようやく原因がわかりました。
どうもセキュリティソフトの ESET が悪さをしていたようです。
解決策というか回避策としては、ESET の設定 -> セキュリティツール から、
「すべてのブラウザーを保護」を OFF にするしかないようです。
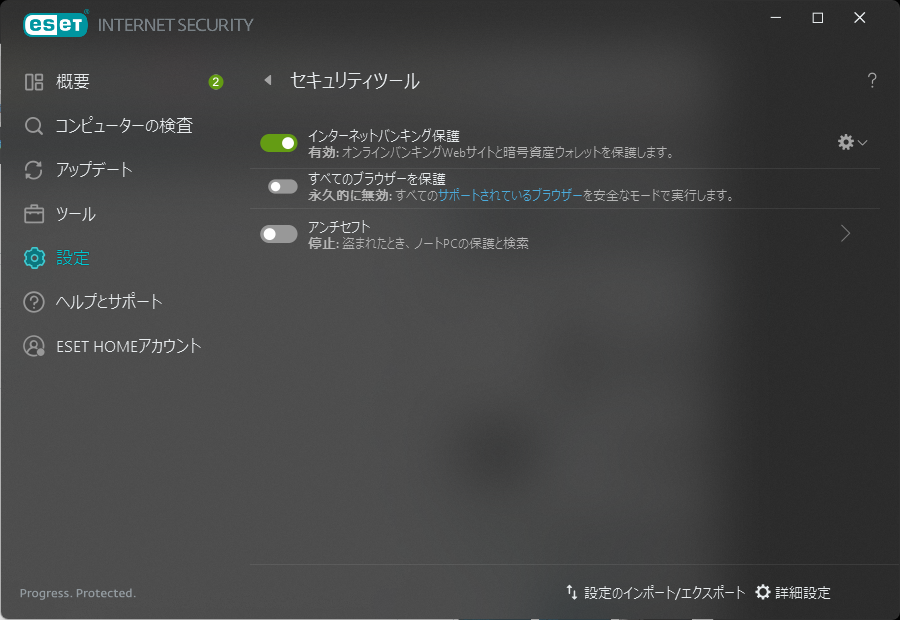
これでかなりの苦痛から開放されました。
他にも困っている人がいたんだなと実感。。
WSL で Docker on GPU (Windows 11)
WSL はとても便利で素敵です。
Docker は Deep Learning フレームワークを使う上で、CUDA ごと面倒を見てくれるので、とても便利で素敵です。
そんな素敵な 2 つを一緒に使えたら...
できるんです。
Windows 10 では Insider プログラムに入らないと使えなかったらしいのですが、
Windows 11 では、標準でできるんです。
それまで Windows 11 に入れ替える気などさらさらなかったのですが、その情報を見て一気に気持ちがぐらつきました。
や・・・やるしかない・・・
Windows 11 へのアップグレード
Windows Update を開いてみると、とてもありがたいお言葉が書かれておりました。
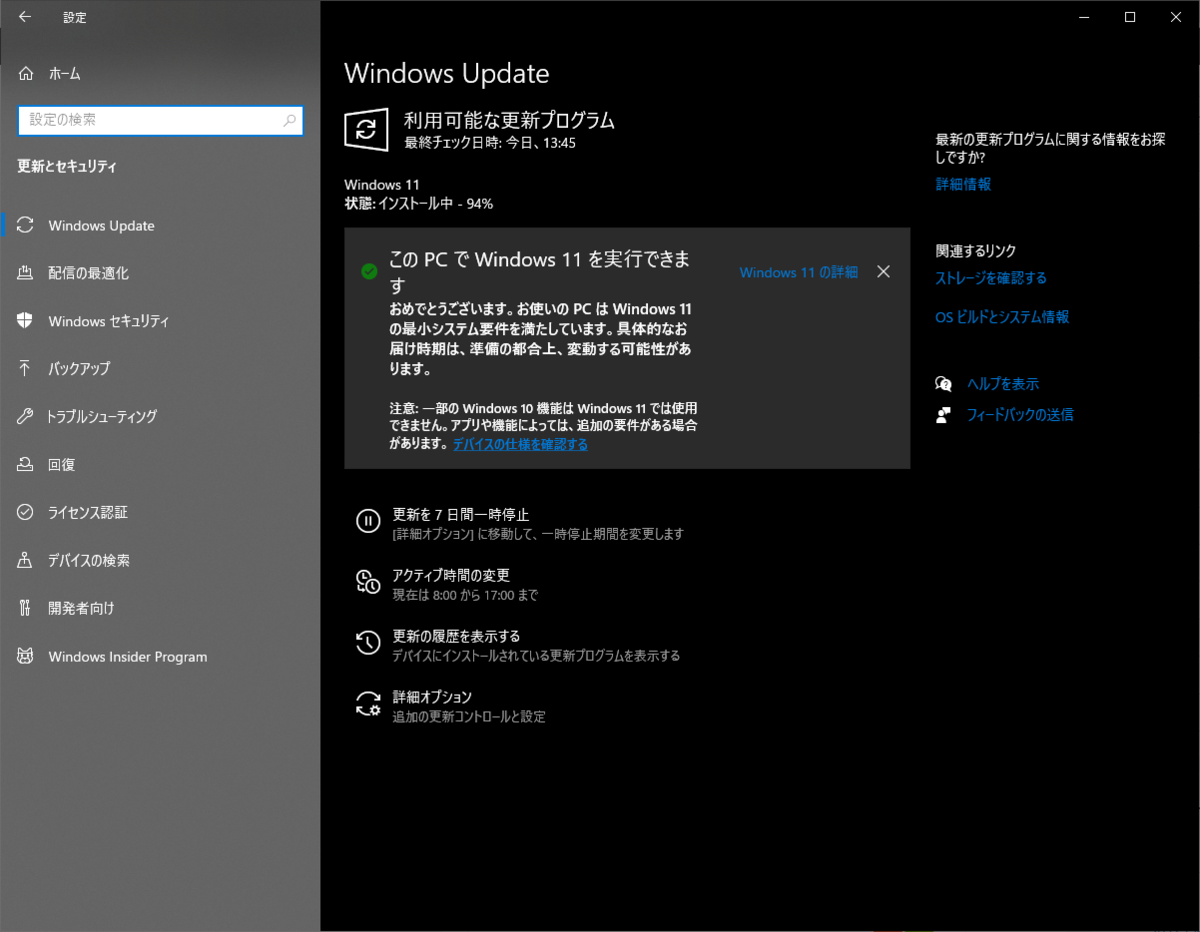
「おめでとうございます。この PC で Windows 11 を実行できます。」
これまでこの文言を見ても、ただアップデートさせたいだけでしょ、としか感じていなかったのですが、私は心を入れ替えました。
素直に「ありがとうございます」と言えるように改心したのです。
ありがたいお言葉に従い、アップグレードをいたしました。
Windows 11 様、無事に来てくれました。
新しいタスクバーとか、まじいらねぇ 本当に最高です。
ありがとうございます。
wt.exe が見つかりません
これまでは Windows キー + x -> i を押して PowerShell を起動していました。
同様にやろうとしたら、Windows キー + x を押した時点で、PowerShell という項目がなく、かわりに Windows ターミナルになっています。
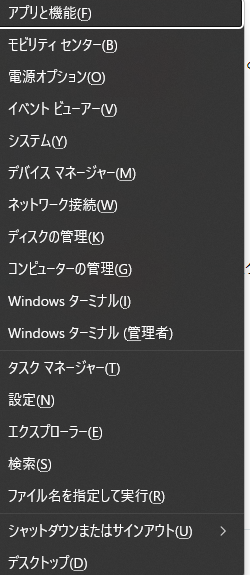
ここで i を押したら、
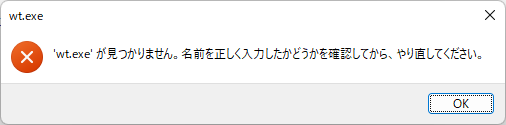
おい...
ショートカットキーがあるのに本体がないのかよ...
WSL のインストール & アップグレード
さてここからが本題です。
Windows ターミナルを開き、まだ WSL が入っていない場合は wsl --install をします。
私の場合はすでに WSL は入っていますが、念のため以下のコマンドでアップグレードすることにしました。
wsl --update
Docker のインストール
まず WSL を立ち上げます。(私の場合は Ubuntu 20.04)
wsl -d Ubuntu-20.04
ここからは WSL の Ubuntu ターミナルで操作します。
まずは Docker をインストールします。
便利なスクリプトがあるようなので活用します。
$ curl -fsSL https://get.docker.com -o get-docker.sh $ sudo sh get-docker.sh
このとき
WSL DETECTED: We recommend using Docker Desktop for Windows. Please get Docker Desktop from https://www.docker.com/products/docker-desktop
という警告が出ますが、無視して進めて良いようです。
最後にユーザー権限で Docker を起動できるようにしておきます。
$ sudo usermod -aG docker $USER
NVIDIA Container Toolkit のインストール
次に、Docker で GPU を使えるようにするための NVIDIA Container Toolkit をダウンロードします。
公式サイトの手順に従うだけですが、一応やったコマンドを書いておきます。
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID) $ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - $ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list $ sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit $ sudo service docker stop $ sudo service docker start
いざ Docker on GPU を試す
いよいよこのときがきました。
試しに NGC にある PyTorch のイメージを試してみました。
$ docker pull nvcr.io/nvidia/pytorch:21.10-py3 $ docker run --gpus all -it --rm --shm-size=8g nvcr.io/nvidia/pytorch:21.10-py3
無事に Docker が起動したので、nvidia-smi を試してみます。
公式ページにも書かれていますが、すべての query には対応していないようです。
# nvidia-smi Thu Jun 9 07:24:56 2022 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 510.68.02 Driver Version: 512.95 CUDA Version: 11.6 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVIDIA GeForce ... On | 00000000:01:00.0 Off | N/A | | N/A 44C P8 14W / N/A | 0MiB / 8192MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+
もうひとつ試しに、PyTorch から GPU が見えるか試してみました。
# python3 Python 3.8.12 | packaged by conda-forge | (default, Sep 29 2021, 19:52:28) [GCC 9.4.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import torch >>> print(torch.cuda.is_available()) True >>>
おお...
ちゃんと見えている...
Windows 11 さん、ありがとうございました。
WslRegisterDistribution failed with error: 0x80070490 が解決した
WSL、便利ですよね。
そんな WSL が、あるときからエラーで動かなくなりました。
おかしいなと思い、WSL 環境を再インストール。
あらためて Ubuntu を入れ直すと、下のエラーが出て Ubuntu の起動すらできなくなってしまいました。
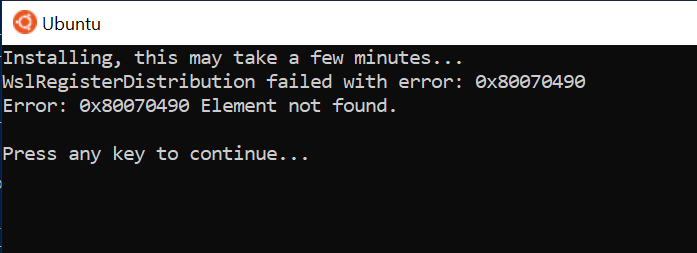
GitHub の WSL のページで Issue を見ると、他にも若干ですが同じことで困っている人がいました。
内容を見てみると、Windows アップデートが怪しいとか、いろんな記述がありました。
でも結局は Windows を入れ直すしかなかった、といったような不吉な記述もあり...
そこまではやりたくなかったので、効果的な解決策を待つこと約半年。
あらためて Issue を覗いてみると、解決方法そのものは書いていなかったのですが、どうやらネットワークドライバーまわりが怪しそうなことに気づきました。
あまり覚えていなかったのですが、よく考えてみると、半年前くらいに仕事で USB3 の産業用カメラのドライバーをインストールしたときに、誤って同時に GigE のドライバーも入れてしまったことがありました。
そのときはネットワークにつながらなくなり、おいおいと思ったのですが、イーサネットのプロパティでチェックを外せばネットワークが使えたので、それでよしとしていました。
ただ GigE ドライバーそのものは残っていました。
ふとそれを思い出し、GigE ドライバーを「削除」してみました。
(削除前のスクショは取り忘れたので、削除後ですが...)
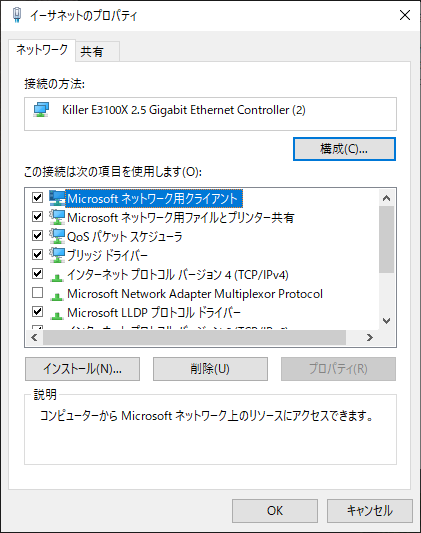
そうしたら WSL が復活...
まじかよ...
というわけで、あんまりいないとは思いますが、WSL が動かなくなって困っている方は、ネットワークドライバーを見ると良いことがあるかもしれません。
ちなみに 2022/06/09 時点で、GitHub の Issue では、効果的な Workaround として以下のようなことが書かれていました。
私は試していませんが、ご紹介だけしておきます。
- I uninstalled the distros using the command > wsl --unregister
- I uninstalled Docker
- I uninstalled Hyper-V
- After restarting the computer, I used the command > wsl --set-default-version 2
- I reinstalled the Ubuntu distro using the command > wsl --install -d Ubuntu
- The Windows Subsystem for Linux instance terminated successfully.
- I verified that the distro is running as WSL 2 with the command > wsl -l -v