Ubuntu から QNAP NAS にバックアップを取る
まえがき
バックアップ用に QNAP NAS TS-431Kを調達しました。
 TS-431K 専用OS QTS搭載 クアッドコア1.7GHz CPU 1GBメモリ 4ベイ ホーム&SOHO向け スナップショット機能対応 NAS 2年保証")
QNAP(キューナップ) TS-431K 専用OS QTS搭載 クアッドコア1.7GHz CPU 1GBメモリ 4ベイ ホーム&SOHO向け スナップショット機能対応 NAS 2年保証
- 発売日: 2020/05/29
- メディア: Personal Computers
ここに、仕事用の様々な PC からバックアップを取ることにします。
Windows からは、QNAP 純正ユーティリティの NetBak Replicator が使えるので、それを使いました。
ただこのツールは Windows 専用。
Ubuntu 用には QSync というツールがありますが、これは Google Drive みたいな感じで、QNAP の特定ディレクトリをマウントするユーティリティのようです。
なので、これを使ってマウントしたうえで、rsync でバックアップを取ることにしました。
QNAP に Qsync Central を設定する
基本的には以下のドキュメントに書いてあるとおりです。
まず最初に QNAP の GUI から App Center を開きます。
そこで Qsync Central を検索してインストールします。
次にメインメニュー -> アプリケーションから Qsync Central を開きます。
共有フォルダーを開き、バックアップ先にしたいディレクトリに権限付与を設定します。
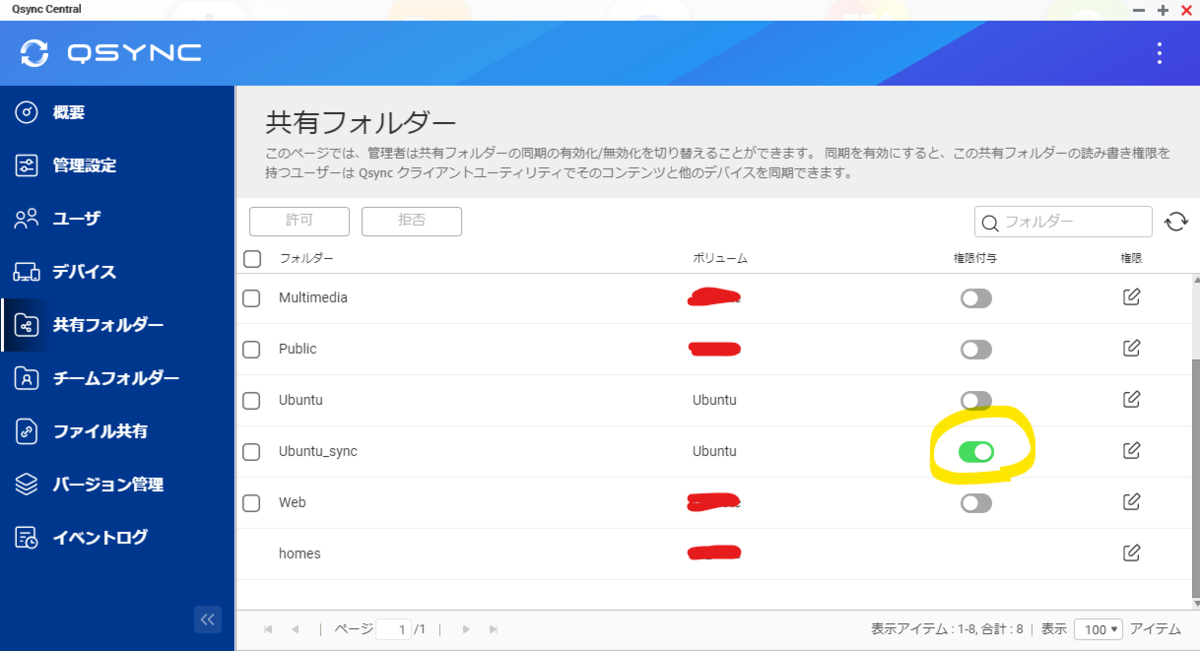
これで QNAP 側の設定は OK です。
Ubuntu に Qsync Client を設定する
Ubuntu で QNAP ユーティリティのページにアクセスし、Qsync の Ubuntu 用パッケージをダウンロードします。

ターミナルを開き、ダウンロード先のディレクトリに移動します。
そこで以下のコマンドを叩きます。
$ sudo dpkg -i <download_file.deb>
インストールすると再起動せよと出るので、指示通りに再起動します。
すると起動後に Qsync Client が自動的に起動されます。
そこで QNAP 側のアドレスや ID を設定し、同期用のディレクトリを指定すれば完了です。
Ubuntu で rsync によるバックアップを行う
まずは rsync をインストールします。
$ sudo apt update $ sudo apt -y install rsync
次に rsync コマンドを発行します。
$ sudo rsync -auv --delete --progress src_path dest_path
src_path はバックアップしたいディレクトリ、dest_path は、さきほど設定した同期用のディレクトリです。
これで、バックアップが行われるようになります。
定期的に実行されるようにする
cron を使えば、定期的にバックアップを実行できます。
私の場合はいくつかのディレクトリをバックアップしたいので、簡単なシェルスクリプトを作って実行させるようにしました。
こんな感じです。
#!/bin/bash echo 'password' | sudo -S rsync -auv --delete --progress src_path1 dest_path1 echo 'password' | sudo -S rsync -auv --delete --progress src_path1 dest_path1
password は sudo 用のパスワードです。
これをすることで sudo が自動的に実行されるようにしました。
最後に cron への設定です。
$ sudo crontab -e
0 3 * * * bash /home/user/backup.sh
これで毎日3時に、バックアップ用のスクリプトが実行されるようになりました。
パスワード入力を省略して SCP コマンドを実行する
背景
簡易的なバックアップのために、定期的にファイルのコピーを行うことになりました。
ある Linux マシンから別の Linux マシンにファイルコピーを行う環境なので、
- 定期的な実行 -> cron
- ファイルコピー -> scp
をそれぞれ使うことにしました。
通常 scp はパスワードの入力が求められます。
そのため cron やシェルスクリプトでそのまま扱いにくいです。
そこで、SSH key を使ってパスワード入力を省略することにしました。
SSH key の生成
scp を実行するマシンを A (ユーザa)、コピー先のマシンを B (ユーザb) とします。
A で以下のコマンドを実行します。
a@A$ ssh-keygen -t rsa
こうすると暗号鍵の保存場所やパスフレーズなどが聞かれます。
パスフレーズは入力しないで Enter します。
すると、~/.ssh/id_rsa (private key) と ~/.ssh/id_rsa.pub (public key) が生成されます。
SSH public key を B に追加
生成した SSH public key を B に追加します。
まず B にユーザ b としてログインし、.ssh ディレクトリを作成します。
すでに .ssh ディレクトリがある場合は飛ばして大丈夫です。
a@A$ ssh b@B mkdir -p .ssh
次に、A の public key を B の authorized_keys に追記します。
a@A$ cat .ssh/id_rsa.pub | ssh b@B 'cat >> .ssh/authorized_keys'
これで準備が整いました。
scp する
scp -i を使うと、パスワード入力を求められずに scp できます。
a@A$ scp -i ~/.ssh/id_rsa ~/file_to_send.txt b@B:/path/to/
SIGNATE で COVID-19 チャレンジ開催
日本版 Kaggle ともいえる SIGNATE で、COVID-19 チャレンジが開催されています。
医療関係者でなくても、データサイエンティストでなくても参加できます。
COVID-19 の早期理解、そして今後の対策のために参加してみてはいかがでしょうか。
SIGNATE COVID-19 Challenge
現時点における日本国内のCOVID-19に関する情報は、国や自治体などで配信方針がバラバラであり、テキスト形式やPDF形式、画像形式などの非構造データで配信されているものも多く、一元的・網羅的でマシンリーダブルかつデータ分析可能な状態になっていないのが実情です。また、罹患者数などの統計データだけではなく、罹患者一人一人に関する感染背景や症状など、できるだけ詳細な情報を網羅的に収集し、データ分析が可能な状態で共有することは、今後の感染対策や治療方針の策定に有用であると考えられますが、このようなデータセットは海外でも未だ公開されていません。
そこで、これらの状況を打破するべく「COVID-19チャレンジ」を開催いたします。
COVID-19 に関する情報は、各自治体ごとにそれぞれのフォーマットで配信されています。
データ解析に使うには、これらのフォーマットを統一し、一つのデータセットにまとめる必要があります。
SIGNATE では、Phase 1 として、まずそのデータセットを構築することを目指しています。
データセット構築がある程度できてきたら、Phase 2 としてデータの解析をするようです。
COVID-19 データセットの構築
以下の Google スプレッドシートを人力で更新していきます。
いろいろな自治体のホームページ等から情報を拾って、このシートに入力していくのがタスクです。
なので、まさに誰でもできます。
でもこのデータセットを作るという作業が非常に重要です。
このデータセットの質によって、今後の解析がうまくいくかどうかも大きく影響されます。
なので、たくさんの人に参加してもらって、質を上げていければ良いのではないでしょうか。
またデータを更新したら、フォーラムに「○○を更新した」という報告をします。
以下は私の投稿例です。

私は SIGNATE を使うのは初めてですが、とても意義のある活動だと思います。
ぜひたくさんの人に参加していただきたいです。